
大模型安全实战课--极客时间课程推荐/优惠
本站非极客时间官网,与官方无任何关系。我们不提供课程下载或详细内容,仅作为课程分享和推荐平台。我们鼓励大家支持正版,尊重创作者的劳动成果,这样不仅能帮助创作者持续产出优质内容,也能让自己获得更好的学习体验。请通过官方渠道购买和学习课程,感谢您的理解与支持。
课程详情
你将获得:
- 系统提升大模型安全治理能力;
- 8 类高频模型风险防御思路与手段;
- 大模型安全攻防演练与案例剖析;
- 即学即用的企业级安全实践指南。
课程介绍
基于大模型能力开发的产品和服务越来越多,大模型安全问题也成了每位拥抱AI的开发者、产品人乃至技术人负责人绕不开的必答题。
在大模型应用的过程中,我们经常产生后面这些疑问:
- “我们项目用开源大模型接了RAG,但老板担心会出安全事故,怎么办?”
- “如果用户给模型输入不合规内容,模型会不会出事?”
- “我们想做一个To C的模型应用,怎么通过备案?”
- “我们接了行业私有数据,怎么保证模型不会把客户数据拿去训练?”
- “听说很多提示词被泄露后会被滥用,怎么保护好这些Prompt?”
- “提示词过滤器如何设计?”
- ……
为此,我们邀请了赵帅老师开设这门《大模型安全实战课》,分享这些年在实际项目中经历过的坑、踩过的雷,以及摸索总结出来的一套系统化的做法。帮助你从理论到实践,真正建立起一整套可落地的安全思路、技术手段和架构策略,让安全原则不仅仅停留在概念上,而是能在AI产品和平台设计中变成可执行的方案、可操作的流程,帮你打通真正的安全落地路线。
课程的知识导图如下。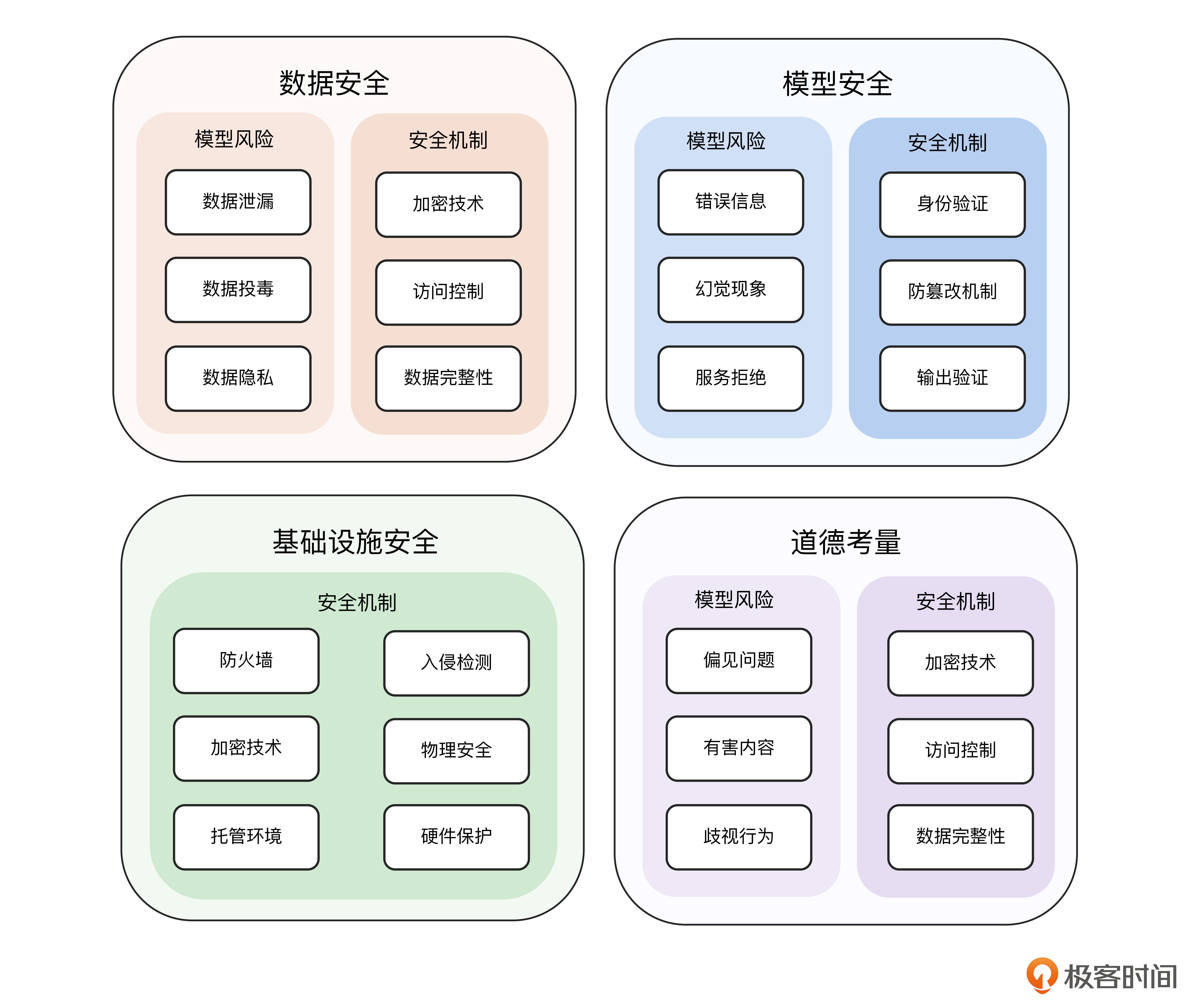
模块设计
为了提升你的模型安全认知水平和实战落地能力,课程里一共设计了四个模块。
启航篇:对大模型安全建设建立系统、科学认知。认识大模型安全的本质与价值,模型的运行机制,识别高频的风险类型,了解大模型安全架构逻辑。
风险篇:针对大模型的高频风险,和你深入探讨“大模型被欺骗”(提示注入、上下文劫持、微调投毒等问题)“大模型被盗窃”(逆向攻击)“大模型说错话”(内容越界、隐私泄露)等诸多现实落地风险的判别和预防,帮你稳步提升“风险识别能力”。
防御篇:在深入理解风险的基础上,学习大模型安全的应对策略,掌握如何通过系统性设计手段构建大模型的“安全防线”。围绕“输入-处理-输出”这一工作流程,我们将学习包括 Prompt 过滤、上下文权限隔离、内容输出拦截与标识、审计日志回溯等在内的核心机制,同时进一步引入如RLHF(强化学习人类反馈)、宪法式 AI、红队测试、系统提示对齐等业界主流安全机制。
企业篇:将安全从“原理”与“机制”层面,进一步推进到“场景实践”的维度。我们将结合真实案例来加强自己的“安全落地工程”的实战能力。这一章精选了多个代表性的具体业务场景,让你掌握如何在具体产品(聊天类助手、编程类助手、教育、金融、医疗、政务等行业智能体)中实现“因地制宜”的模型安全控制。
课程目录
开篇词
- 开篇词|大模型安全不是黑科技,是新的基本功
- 课前热身|10道题帮你测试 AI “安全分”
- 直播回放|不想大模型“裸奔”?安全建设三步走!
启航篇
- 01|初识安全:如何理解大模型安全?
- 02|模型机制:生成式大语言模型的运行逻辑全景图
- 03|风险类型:8类高频安全威胁,你遇到几个?
- 04|安全架构:如何构建一个有边界的大模型系统?
风险篇
- 05|提示注入攻防战(上):大模型“听谁的”?
- 06|提示注入攻防战(下):反制机制与攻防演练
- 07|微调数据“投毒”与模型“后门”
- 08|模型“盗窃”与逆向算法攻击
- 09|敏感信息防范:模型会“记住”用户隐私吗?
- 10|有害信息生成与公共信息风险
- 11|拒绝服务攻击:Prompt也能让模型宕机?
- 12|绕过安全防护的技术与挑战
防御篇
- 13|提示词过滤净化:第一道防线如何构建?
- 14|输出内容把关:如何精准识别违规生成?
- 15 | 黄赌毒等内容治理:AI输出伦理边界谁来定?
- 16 | 舆情与品牌防护:防止模型“伤人伤己”
- 17|对齐技术:RLHF、RLAIF与Constitutional AI与行为控制
- 18|数据生命周期安全:从采集到销毁的全景管理
- 19|安全运维:如何构建“大模型的SRE体系”
- 20|红队测试与安全审计:主动发现比事后补救更重要
企业篇
- 21 | 聊天助手的安全挑战与越狱防护机制
- 22|编程助手如何防止代码注入与权限漏洞?
- 23|搜索与问答系统如何识别“幻觉”与事实偏差
- 24 | 教育类产品中的儿童保护与内容审查机制
- 25|金融、医疗、政务行业部署私有大模型的安全要点
- 26|可解释性与审计:模型如何“自证清白”?
- 27|融合模型的安全新维度
- 28|联邦学习与分布式安全机制
- 29|安全评估体系:怎么衡量“是否安全”?
- 30|模拟提示注入与防御策略演练
- 31|构建简易版安全过滤器
- 32|企业级安全应用加固案例
- 33|大模型安全的未来趋势与演进路线
结束语 & 结课测试
- 结束语|AI浪潮波澜四起,安全能力保驾护航!
- 结课测试|期待你的满分答卷!
作者介绍
推荐





